Abstract:
====================
This project is about parallel astronomic event detection in long time series using graphical processing units (GPU). The objective is to match pre-generated templates of various parameters to every possible segment of the time series, by using a sliding window cross correlation. The data for this project comes from a to be proposed satellite, called whipple, which is expected to monitor 10,000 stars at 40hz around the clock. This is a total of 3.45x10^10 readings per day. The templates length for this project was set to 20 points, but will be adjustable in later version to allow for longer events. Sample rate was another constant for this project, but will have to be considered for future development.
(Please excuse the rushed presentation, it was necessary to keep it to 2 minutes)
What are we trying to detect?
====================
We are trying to detect trans-neptunian objects by monitoring the background light of stars, when one of these objects passes between a star and the earth or observer, the object blocks and refracts some of the light which we would see from earth. By recording the change in light coming from the star and by analyzing the resulting time series, or lightcurve, we can derive many parameters about the object itself, such as its size, speed and distance from earth.

Source: TAOS Collaboration; Pavlos Protopapas.
Fig. 1: Loop of an Occultation as seen by a telescope. (event occurs in the center of the animation)
How it works
===================
The comparison between a given template and a section of the lightcurve is done by cross correlation, the highest correlation value is the best match.
The correlation is calculated by the following function:
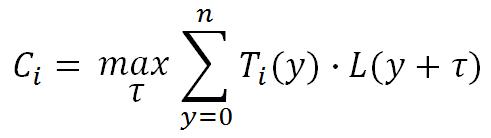
Fig. 2: Ci(t) is the maximum cross correlation of Ti() * L(); where Ti is a template i of length n and L is a segment of the lightcurve at offset t, also of length n

Fig. 3: Cmax is the maximum correlation of all Ci; where i is the index of the best matching template
The Inner Workings:
===============
PreProc_Templates():
This function reads all templates in a given directory structure and slices them to the right length while also normalizing them before concatenating them to one long array for easier accessing. This array is then stored in a binary file for faster loading in the search function. It also creates a dictionary in the same directory, which in the same order as in the array list all file names of the read-in templates for reverse lookup after the search has been completed. This function will in future version also store the parameters by which the templates were generated.
Search_LC():
First this function reads in the binary file of all the templates, as well as the lightcurve to be searched. These are first stored in system memory but then transferred to device memory on the GPU as "textures". Next it launches the kernel across 30 blocks, which is the number of multiprocessors of the GTX285, with 64 threads per block. Each thread is responsible to calculate the correlation between one specific template and every piece of the lightcurve. After the kernel has finished it reads back 30 float3's (a stuct containing 3 floats;x, y and z), which contain the highest correlation value obtained in one block, the index of that template and the index of the location this correlation was calculated along the lightcurve. Then it finds the max of the 30 float3s, which in turn is the best matched event in the lightcurve.
gpucorrmultiplex():
all the magic happens: This is the GPU kernel, it gets launched over b blocks of t threads, where b=template_cnt/t. This ensures that there is one template for each thread. At the moment it can only take a number of templates evenly divisible by the number of threads. In this version the number of threads/templates per block is 64 with a template length of 20 points. These and 15/16 segments of lightcurve with length 20 are loaded into shared memory to speedup repeated reading of the same data. The numbers for the number of threads/templates, lightcurve segments and their respective lengths for a given block, are chosen not to exceed half of the available shared memory to make it possible for different blocks to be active on the same multiprocessor at the same time. In future versions these numbers will change to better optimize for coalesced reads. At the moment all reads are designed to read sequential parts of memory from texture memory when loading in the templates or when the LC segments get updated.
This kernel works by the following concept, it first loads in the templates used in that specific block, these will stay constant for the runtime of the block. Secondly it enters loop A which will load in the first 15 segments of 20 points of the lightcurve and then will enter a second loop, B, which will shift the current comparison window by one after every iteration. Inside loop B each thread finds its correlation between its own template and the current 20 point segment of the lightcurve, then all threads synchronize and find the best correlation between the 64 threads, this is saved in a temporary variable in thread 0. Then loop B shifts the comparison window over by one and will repeat the last step, until the current 15 by 20 point segment is eaten up and then loop A will load in the next 15 by 20 point segment and loop B starts all over. This series of events recurs until the entire lightcurve has been processed. The last step is for each block to write its best match to an array in global memory.
Performance:
===============
In our fist test runs, naieve implementation on GPU(400 templates of 20 points and 8600 point lightcurve), we achieved 3.68 gigaflop/s. In our final implementation(1950 templates of 20 points and 8600 point lightcurve) we achieved 17.19 useful gigaflop/s. Just as a reference point, the naieve CPU implementation got 1.44 gigaflop/s.
| # of Templates | Template length |
LC length | Flops per |
Time | Resulting GFLOP/s | |
| Naieve GPU | 400 | 20 | 8600 | 2 | 37.2ms | 3.68 GFLOP/s |
| Final GPU | 1950 | 20 | 8600 | 2 | 39ms | 17.19 GFLOP/s |
| CPU | 1950 | 20 | 8600 | 2 | 683.2 | 1.44 GFLOP/s |
Features:
===============
Version 0.1: (as submitted as final)
Version 0.2:
Version 0.3:(still under development)
Links:
===============
Any questions, comments, insults or suggestions please email the above mentioned email. - Thank you
